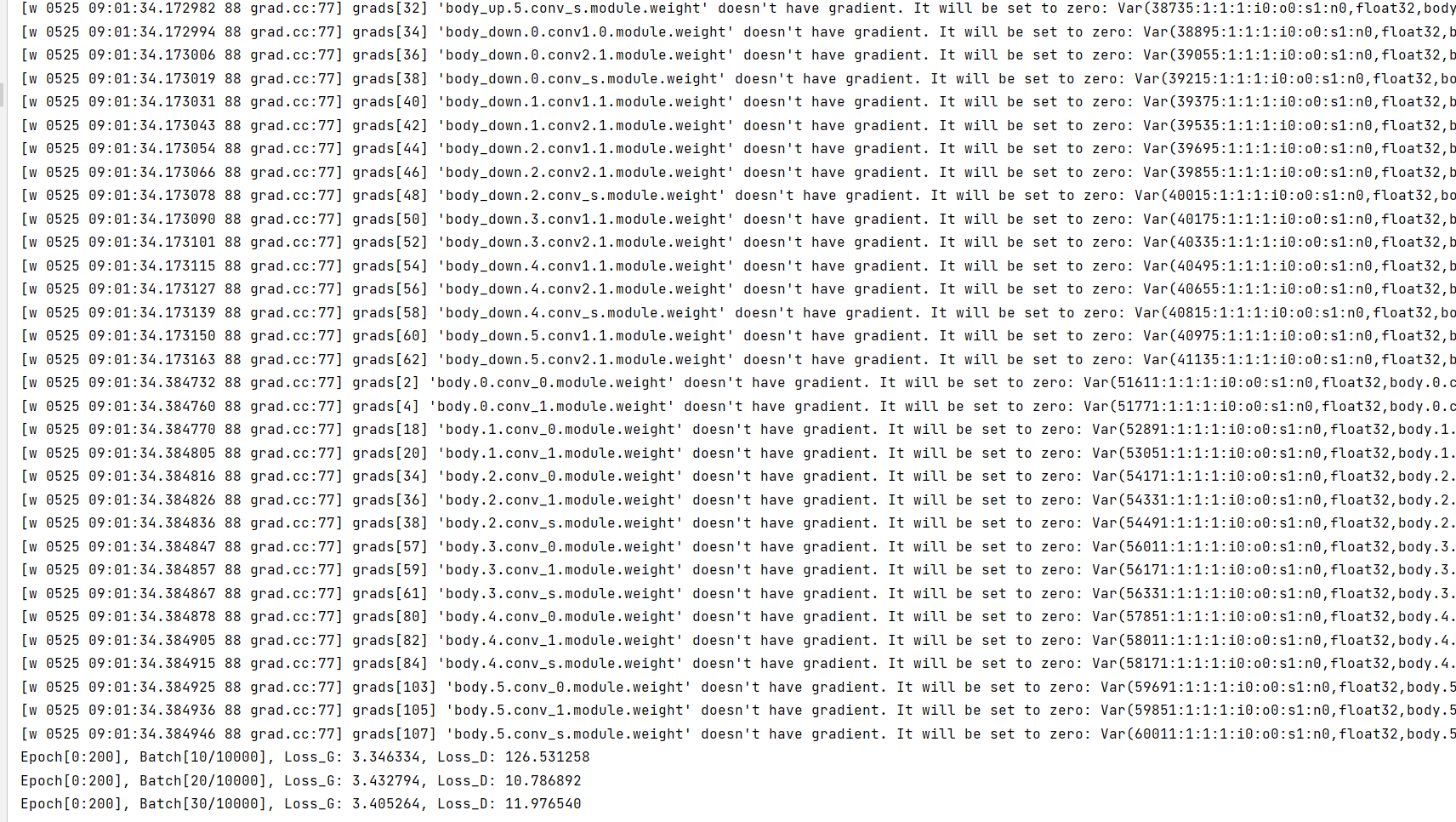
为了让GAN模型训练更加稳定,加入spectral_normalization,jittor没有像torch提供相关接口。所以我参考建议jittor添加spectral_norm以对标torch.nn.utils.spectral_norm 实现如下。
import jittor as jt
import jittor.nn as nn
from jittor.misc import normalize
class SpectralNorm(nn.Module):
def __init__(self, module, name='weight', power_iterations=1, eps=1e-12):
super(SpectralNorm, self).__init__()
self.module = module
self.name = name
self.eps = eps
self.power_iterations = power_iterations
# if not self._made_params():
# self._make_params()
def _update_u_v(self):
weight = getattr(self.module, self.name)
# del self.module._parameters[self.name]
with jt.no_grad():
weight_mat = weight
height = weight_mat.size(0)
weight_mat = weight_mat.reshape(height, -1)
h, w = weight_mat.size()
u = normalize(jt.randn([h]), dim=0, eps=self.eps)
v = normalize(jt.randn([w]), dim=0, eps=self.eps)
if self.module.is_training():
# with jt.no_grad():
for _ in range(self.power_iterations):
v = normalize(jt.nn.matmul(weight_mat.t(), u), dim=0, eps=self.eps)
u = normalize(jt.nn.matmul(weight_mat, v), dim=0, eps=self.eps)
# sigma = torch.dot(u.data, torch.mv(w.view(height,-1).data, v.data))
sigma = jt.matmul(u, jt.matmul(weight_mat, v))
weight = weight / sigma
# setattr(self.module, self.name, weight / sigma)
# else:
# setattr(self.module, self.name, weight)
# self.module._parameters[self.name].start_grad()
self.module._parameters[self.name] = weight
self.module._parameters[self.name].start_grad()
def execute(self, *args):
self._update_u_v()
return self.module.execute(*args)
但还是会遇到loss直接飞了的情况。还遇到了权重出现没有梯度的问题,start_grad但仍报没有梯度的警告,如下:
大家康康这样实现(或者有更好的实现)spectral norm有什么问题吗?已经调试好几天了…
您好,您可以在self.module._parameters[self.name].start_grad()这句话前面分别打印一下shape和requires_grad信息么?
分别加入这句话打印一下。
print(self.module._parameters[self.name].shape, self.module._parameters[self.name].requires_grad)
self.module._parameters[self.name] = weight
# print(self.module._parameters[self.name].requires_grad)
if not self.module._parameters[self.name].requires_grad:
self.module._parameters[self.name].start_grad()
非常感谢~~ 下面的改成这样之后,grad的问题就没了。但没有达到预期的结果,上面jittor的实现几乎是torch实现的“翻译”…
可以自己检查代码逻辑,看看是不是不小心detach断了梯度。也可以采取register_hook和opt_grad两种方式来调试具体是哪里没有梯度。具体使用方式参考下面代码。
import jittor as jt
n = 5
G = jt.nn.Sequential(
jt.nn.Linear(n,n),
jt.sigmoid
)
D = jt.nn.Sequential(
jt.nn.Linear(n,n),
jt.sigmoid
)
noise = jt.randn(1,n)
loss = jt.nn.mse_loss
target = jt.randn(1,n)
optim_D = jt.optim.SGD(D.parameters(), 0.1)
optim_G = jt.optim.SGD(G.parameters(), 0.1)
print(D.parameters())
print(G.parameters())
# optim D
img = G(noise)
D_out = D(img)
print("D out", D_out)
D_out.register_hook(lambda x: print("D_out grad", x))
D_loss = loss(D_out, target)
optim_D.step(D_loss)
print("loss", D_loss, img, D(img))
print("grad", D[0].weight.opt_grad(optim_D))
# img = G(noise)
G_loss = loss(img, target)
optim_G.step(G_loss)
print(D.parameters())
print(G.parameters())
我们为大家复现了 SpectralNorm,如果大家使用的时候有问题可以联系我们。
class SpectralNorm(nn.Module):
def __init__(self, module, name='weight', power_iterations=1, eps=1e-12):
super(SpectralNorm, self).__init__()
self.module = module
self.name = name
self.power_iterations = power_iterations
self.eps = eps
if not self._made_params():
self._make_params()
def l2normalize(self, v):
return v / (v.norm() + self.eps)
def _update_u_v(self):
u = getattr(self.module, self.name + "_u")
v = getattr(self.module, self.name + "_v")
w = getattr(self.module, self.name)
height = w.shape[0]
for _ in range(self.power_iterations):
v.assign(self.l2normalize((w.view(height,-1).t() * u.unsqueeze(0)).sum(-1)))
u.assign(self.l2normalize((w.view(height,-1) * v.unsqueeze(0)).sum(-1)))
sigma = (u * (w.view(height,-1) * v.unsqueeze(0)).sum(-1)).sum()
getattr(self.module, self.name).assign(w / sigma.expand_as(w))
def _made_params(self):
try:
u = getattr(self.module, self.name + "_u")
v = getattr(self.module, self.name + "_v")
w = getattr(self.module, self.name)
return True
except AttributeError:
return False
def _make_params(self):
w = getattr(self.module, self.name)
height = w.shape[0]
width = w.view(height, -1).shape[1]
u = jt.empty([height], dtype=w.dtype).gauss_(0, 1)
v = jt.empty([width], dtype=w.dtype).gauss_(0, 1)
u = self.l2normalize(u)
v = self.l2normalize(v)
setattr(self.module, self.name + "_u", u.stop_grad())
setattr(self.module, self.name + "_v", v.stop_grad())
def execute(self, *args):
self._update_u_v()
return self.module.execute(*args)