Transformer 已经在自然语言处理任务中取得了巨大的成功,并且在图像处理任务上也表现出了巨大的潜力。清华大学图形学实验室博士生国孟昊等成功将Transformer 推广到三维点云处理上,并在点云分类、点云部件分割和点云法向量估计任务上取得了state-of-the-art 的效果。
Transformer for Point Cloud
由于点云数据自身的不规则性和无序性,我们不能直接在点云上使用卷积神经网络进行处理。为了使用深度学习来处理点云相关的任务,我们需要设计一种具有排列不变性并且不依赖欧式空间点的连接关系的算子来处理点云。Transformer中的核心部分是注意力机制,注意力机制本身就是一种排列不变并且不依赖于点之间连接关系的算子,非常适用于处理点云数据。既然 Transformer自身满足点云处理的要求,那么 Transformer 到底能不能推广到点云上去呢?答案是肯定过的!
清华大学图形学实验室提出了用于点云处理的 Transformer,Point Cloud Transformer (PCT);并在Github上开源了基于计图(Jittor)框架的源代码。
图1 PCT的网络架构
PCT的整体架构如上图所示。大致可以分成三个部分:输入嵌入部分、注意力层和分类分割头部。
1. 输入嵌入部分
PCT提出了两种嵌入方式,分别是点嵌入和邻域嵌入。输入嵌入的目的是将点云从欧式空间 xyz映射到高维空间(文章中使用的是128维空间)。点嵌入是仅考虑单点的信息,使用共享的多层神经网络,将点云映射到高维空间。邻域嵌入则不仅仅考虑了单点,还通过使用了KNN考虑了每个点的邻域信息,通过这种邻域嵌入的方式将点嵌入到高维空间。
2. 注意力层
PCT使用了两种不同的注意力层,self-attention 和 offset-attention。Self-attention 是 Transformer 文章中使用的注意力机制,但是它直接作用在点云上效果并不是很理想。为了使得注意力层有更强的表达能力,作者结合了图卷积中的拉普拉斯算子和自注意力机制,提出了offset-attention,该层也表现出了比 self-attention 更好的性能,两者的具体结构如下图所示,他们的区别在于标准化的顺序以及是否有特征之间的减法操作。
图2 PCT的注意力层
3. 分类分割头部
针对不同的任务,分类分割最后的处理略有不同。对于分类,我们对经过注意力层之后的特征直接做Pooling 操作,然后通过全连接层和Dropout 层得到最后的输出。对于分割,我们在做完Pooling 后,像 PointNet 一样,先进行repeat 和 concat 操作,再使用全连接层和Dropout层得到最后的输出。
4. 实验结果
首先,我们可视化了注意力层的 attention map (五角星标注了查询点)。
图3 PCT注意力层的attention map及分割结果
表1给出了ModelNet40 上的分类结果的对比实验,表中P代表位置,N代表法向,相应的数据来自引用的论文。如果追求更高的性能,而忽略计算量和参数,可以在输入嵌入模块中加入邻居嵌入层。三层邻域嵌入可以达到93.4%的分类精度。
表1 ModelNet40 上的分类结果对比
表2给出ModelNet40 上的法向量估计的对比实验结果,表中的误差是法向量的余弦距离的平均。
表2 ModelNet40 上的法向量估计对比
表3给出了ShapeNet 上部件分割的对比实验结果。pIoU是平均的交并比,相应的数据来自引用的论文。同样,如果追求更高的性能,而忽略计算量和参数,三层邻域嵌入便可以达到86.6%的分类精度。
表3 ShapeNet 上部件分割的对比
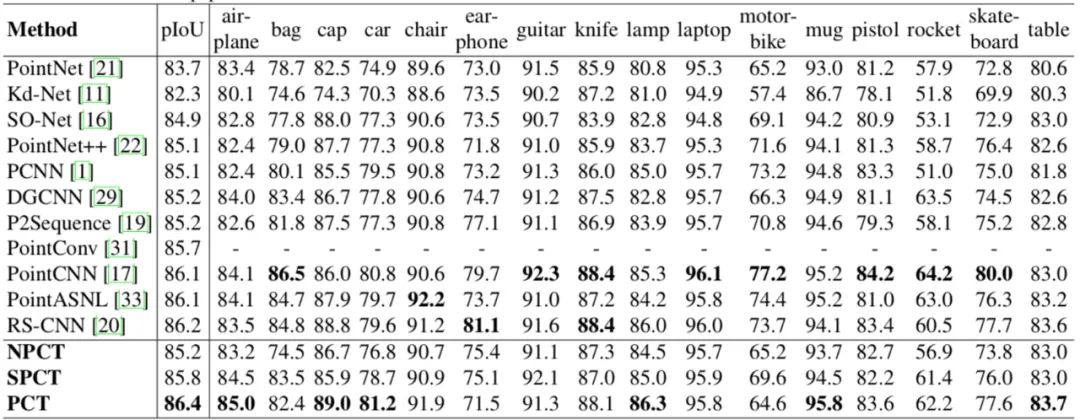
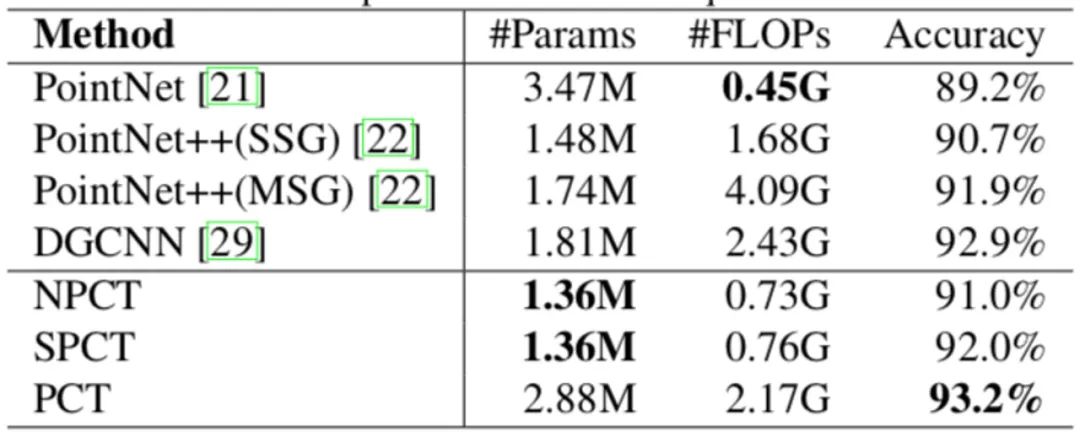
表4给出了网络的参数以及计算量的统计。
表4 PCT网络的参数以及计算量的统计
下图给出模型分割结果的可视化效果。
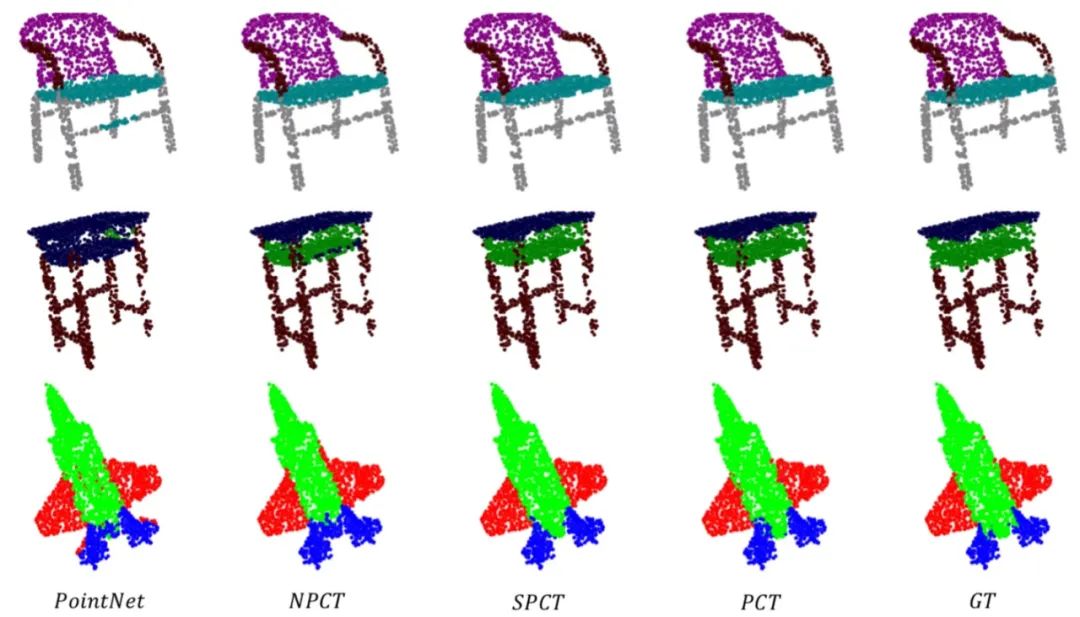
图4 PCT与PiontNet及Ground Truth的分割结果对比
点击原文阅读,可以下载本文的pdf。
参考文献
- Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R. Martin and Shi-Min Hu, PCT: Point Cloud Transformer,