随着深度相机的普及以及VR/AR技术的蓬勃发展,三维重建技术近年来发展迅速,并日益受到学术界和工业界的重视。三维重建系统可以通过采集深度相机的连续RGB-D视频流,在实时对相机自身进行定位的同时,还可维护整个三维场景的表示,因此用户只需用相机对场景进行“扫描”,就能轻松恢复出三维场景信息。
传统的重建方法所使用的两种经典表示:即“截断符号距离场”或“表面元素”的表示方式没有考虑到任何的场景先验,且表示场景所需的大规模参数量也会导致内存占用率大。
为此,清华大学图形学实验室的黄家晖、黄石生和宋浩轩等在CVPR2021发表论文,提出了一个新颖的三维在线重建系统DI-Fusion。

该系统在三维表示上和传统方法拥有显著的区别,采用深度网络建模的局部隐式场对场景几何进行拟合,并支持相机位姿的计算以及增量式几何融合。

图1 DI-Fusion的重建效果
基于计图(Jittor)框架的代码已在GitHub开源:
1. PLIVox场景表示
DI-Fusion将场景划分成等距排列、稀疏分配的概率局部隐式体素PLIVox,每个体素边长约为一分米,体素内的局部几何结构由隐式场表示,定义为输入三维坐标、输出符号距离的多层感知机(MLP)的零势面,该MLP同时还会输出该处的不确定度用于更精确的几何建模。
本文使用的MLP网络权值学习于大规模三维数据集,因此融合了有效的几何先验。与该MLP(解码器)对应的还有相关的编码器,输入观测点云,输出描述几何的隐向量。下图是PLIVox的网络结构。
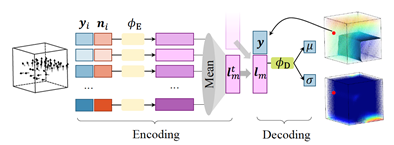
图1 PLIVox网络结构
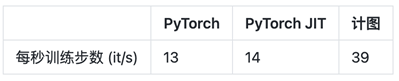
得益于Jittor框架采用的元算子融合以及统一计算图技术,PLIVox内部网络执行的效率大大提高,下表对比了使用Jittor框架和使用PyTorch框架的训练速度,训练同一个epoch,Jittor所用的时间仅有PyTorch的三分之一,原需要训练1-2天的模型,可以在半天内取得较好的收敛效果。
表1 Jittor和PyTorch训练速度对比
2. 相机位姿计算与几何融合
对于每一个新来的RGB-D点云观测,首先需要将其和已有的隐式场表示进行对齐:一个正确的相机位姿能够使得输入每个点处的符号距离为零,由于隐式场已经建模了连续的符号距离,所以可以直接求得符号距离关于位姿的导数,进行迭代式的位姿计算。
接下来需要将新的观测融合到隐式场表示中,由于PLIVox网络在训练的过程中,隐向量已经可以较好地描述局部几何,且所有的点云观测采用均值加权,因此,不同于以往的符号距离场加权融合,我们在隐向量层面上直接进行加权融合,效果如下图所示。
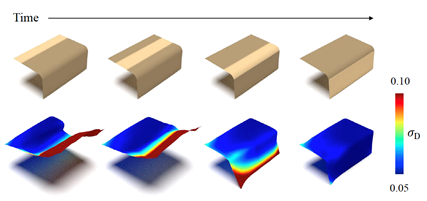
图3 在隐向量层面上直接进行加权融合
3. 系统架构
DI-Fusion系统架构类似于经典的重建系统,输入了本帧RGB-D观测之后,首先求得该帧的相机位姿,接着将观测融合到已有的隐式场几何中;得益于隐式场表示的灵活性,我们可以方便地将其转换成其他表示方式,例如点云、三角网格、体素等等,并通过观测的RGB信息为输出几何施加贴图颜色。
4. 实验结果
DI-Fusion在相机定位准确性上取得了先进的水平,下表对比了本系统和传统表示方法的相机轨迹误差:
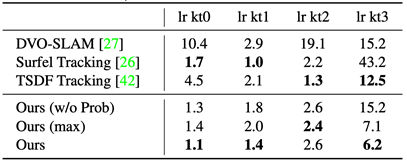
图4. 相机轨迹误差
相对应的定性结果如下图所示 (ICL-NUIM数据集):

图5. 定性结果
下面给出真实扫描场景ScanNet的部分重建结果。


图6. 真实扫描场景的重建结果
本方法在取得较高的重建精度的同时,表示场景所需的参数量也大大减小,下图给出了重建同一个场景时,不同的方法对内存的有效占用随时间的变化曲线。
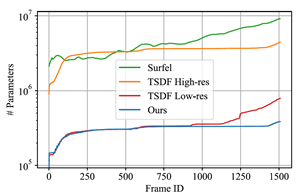
图7. 不同的方法对内存的有效占用的对比
下面是三维在线重建系统DI-Fusion的视频展示:
点击下方“阅读原文”,可下载本文的pdf。
参考文献
Jiahui Huang, Shi-Sheng Huang, Haoxuan Song,Shi-Min Hu. DI-Fusion: Online Implicit 3D Reconstruction with Deep Priors. CVPR2021. https://arxiv.org/pdf/2012.05551.pdf