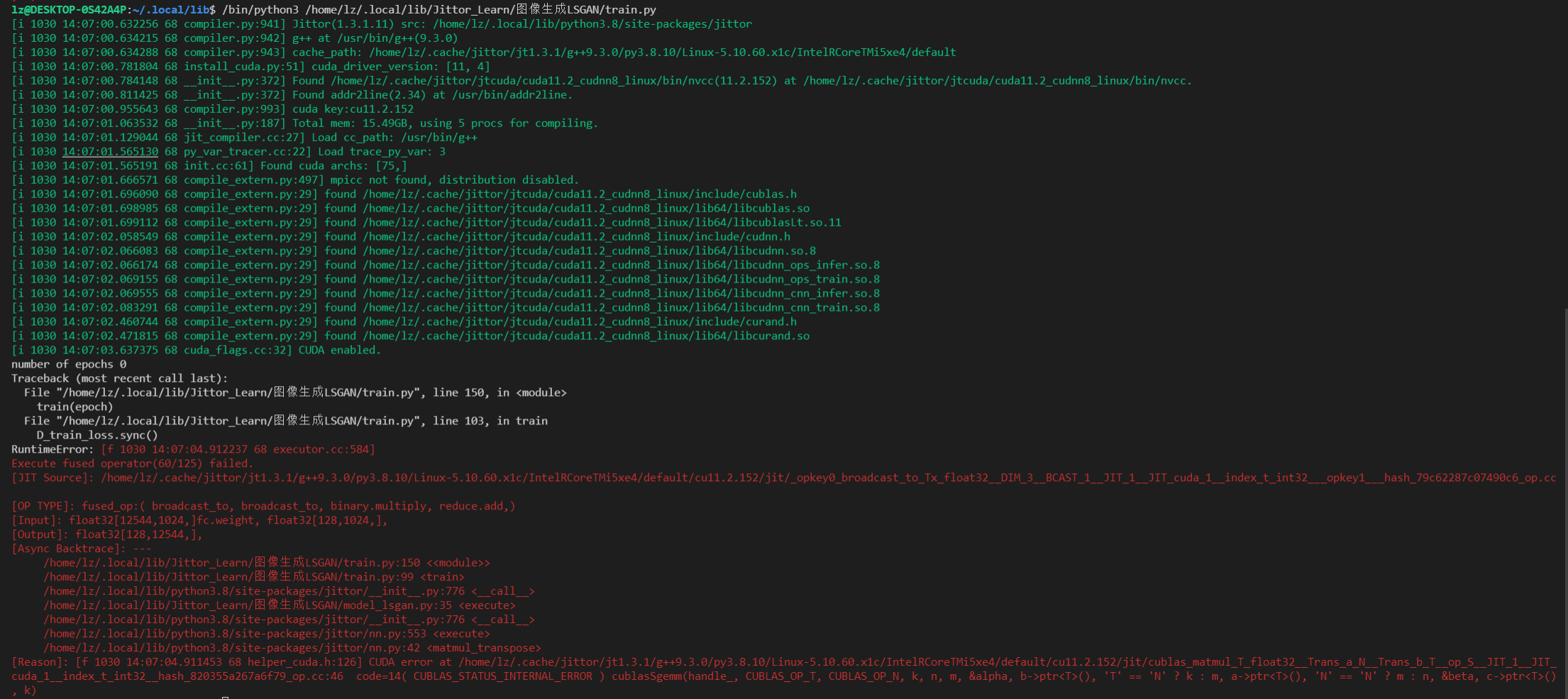
我已经用CPU训练完成了基于MNIST图片分类模型,但在用GPU训练模型(jt.flags.use_cuda = 1)时一直卡在了第1Epoch的99%,并且报错。
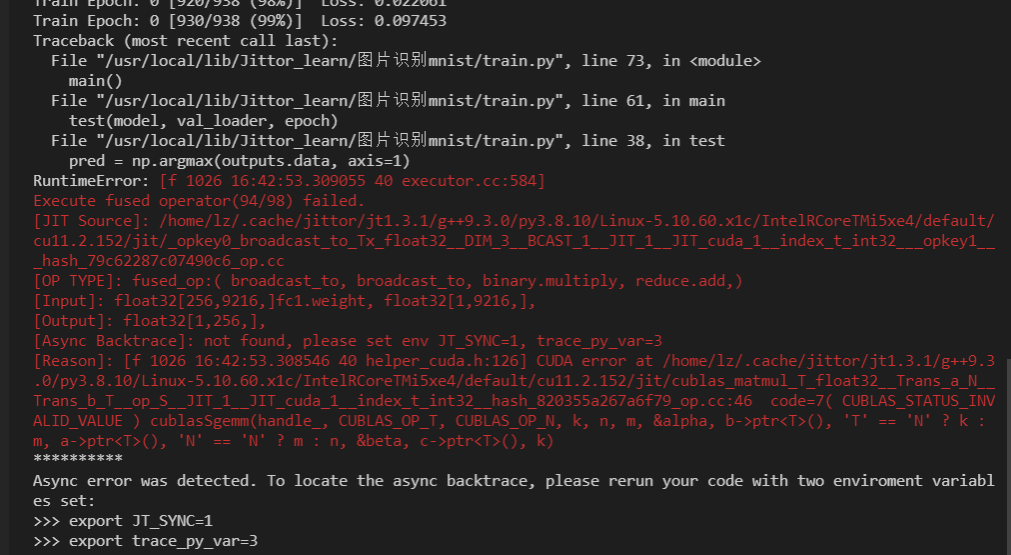
请问有人知道这种情况怎么解决吗?
您可以按照提示,设置运行以下命令,设置环境变量,再运行看结果来定位更准确的信息吗?
export JT_SYNC=1
export trace_py_var=3
也有可能是 conda 的问题,可以运行 unset LD_LIBRARY_PATH,从而防止 conda 的 cuda 环境和 jittor 使用的 cuda 混淆。